


How structured ML models add calibrated belief, uncertainty tracking, and action selection to make LLM-driven agents efficient, stable, and auditable.
Every conversation has a goal: assess risk, complete a task, or influence a user decision. To reach that goal, the system must gather evidence by asking questions. But the objective isn't to ask everything. It's to reach decision confidence with the minimum necessary interaction.
This isn't only an efficiency concern. It's a customer experience constraint. In real systems, customers are part of the loop. Every additional question increases friction, abandonment risk, and potential loss of trust. The system must continuously balance the trade-off between decision confidence and interaction cost.
Decisions must also be stable. In production systems, unstable risk scores don't just reduce accuracy. They break analytics, make iteration impossible, and prevent the system from maintaining a coherent internal state. If similar conversations produce different trajectories, the system becomes difficult to debug, evaluate, or govern.
At Charm, we addressed these problems by rethinking the role of traditional ML in agentic systems. The result is a hybrid architecture where classic ML doesn't just predict outcomes, it actively guides the conversation toward efficient, stable decisions.
Where LLMs Fall Short
While building conversational decision systems at Charm, we found that these two requirements (efficient evidence gathering and decision stability) are exactly where pure LLM-based approaches start to break down.
LLMs excel at interpreting language and generating plausible hypotheses. But when we used them as the primary decision engine, two recurring failure modes emerged:
Instability. Risk estimates fluctuated across similar conversations, and even across turns within the same interaction. This made it difficult to maintain a coherent conversation policy and rendered offline evaluation unreliable.
Lack of control. Without an explicit belief state or uncertainty signal, the system struggled to consistently prioritize high-value questions or determine when sufficient evidence had been gathered to act.
A Hybrid Architecture: ML as Both Predictor and Controller
We addressed both problems by rethinking the role of traditional ML in agentic systems.
Classic ML still handles P(y|x): the probability of an outcome given the evidence we've observed. This provides calibrated, consistent risk estimates. What do we think is happening, and how sure are we?
But it also takes on a new role: guiding the conversation itself. By helping estimate the expected uncertainty reduction of candidate actions, traditional ML enables principled action selection. Conceptually, we select the action that minimize E[Uncertainty | Evidence]. What's the most efficient path to a confident decision?
This helps the agent choose the most informative next question toward a defined objective: reaching a safe, high-confidence decision with minimal customer and operational cost.
High uncertainty becomes actionable: it tells the agent which questions will reduce uncertainty the fastest. In practice, systems often bias this reduction, either toward surfacing hidden risk signals earlier, or toward confirming legitimacy quickly to reduce customer friction. The choice depends on product and policy priorities. Either way, you can inject domain knowledge into the decision loop while keeping the score stable and auditable.
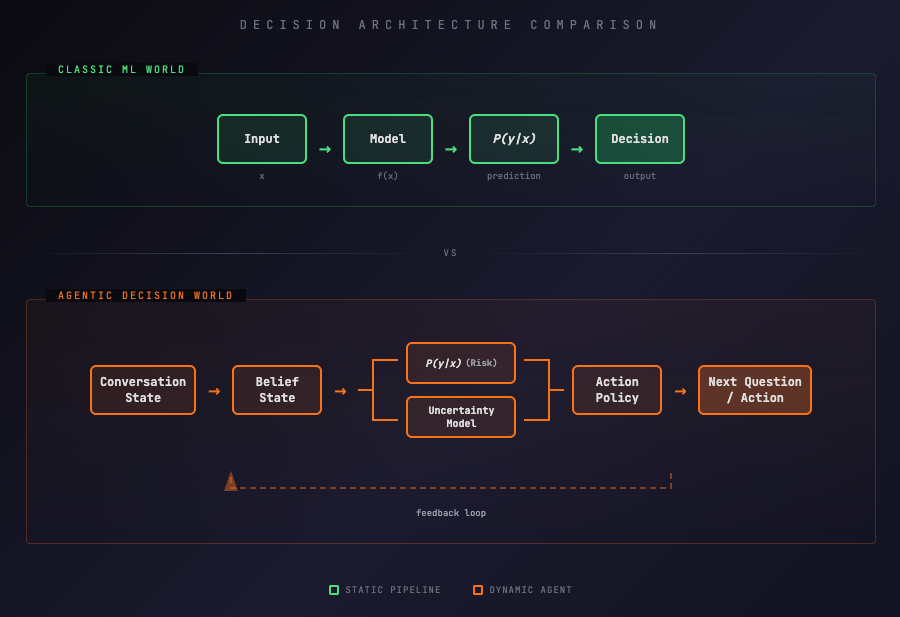
Decision Architecture of Predictive vs Agentic Systems: Classic ML pipelines optimize a single prediction step. Agentic systems continuously update beliefs, combine risk and uncertainty, and select the next action: turning prediction into decision control.
Why Not Reinforcement Learning?
At first glance, this problem seems tailor-made for reinforcement learning. And offline RL methods have made real progress in sparse-reward, high-stakes domains.
But conversational fraud and risk systems operate in environments where states are ambiguous, rewards are delayed or sparse, and safety constraints are strict. Interpretability and auditability are non-negotiable for compliance.
In practice, we find that combining traditional ML, structured belief modeling, and LLM reasoning provides a more controllable and interpretable approach for production decision systems.
Starting Without Labeled Data
Early on, you often don't have enough labeled data to train either model reliably. In fraud-like domains, labels can be delayed, noisy, or expensive.
In that setting, we've found it effective to start with a structured scoring layer that produces:
- A consistent risk score for P(y|x)
- An explicit uncertainty measure that drives E[Uncertainty | Evidence] given an action
We built a generic decision framework that makes it easy to connect domain knowledge, evaluation insights, and customer or institutional preferences directly into the agent's decision loop.
For P(y|x): We use a sigmoid-based formulation to produce calibrated, bounded risk estimates, ensuring scores stay in a stable, interpretable range even as evidence accumulates.
For uncertainty: We use an entropy-based formulation to quantify uncertainty over the system's current belief state, which naturally peaks when evidence is conflicting or sparse.
This separation lets us keep risk estimation stable and interpretable while treating uncertainty as a first-class control signal for conversation planning. We plan to cover the specific modeling choices and implementation details in a dedicated follow-up post.
A Concrete Example
A customer says: "I'm trying to send a large wire for an investment opportunity. The bank is blocking it. I need you to approve it."
An LLM-only system might respond by helping unblock the transfer or asking for standard verification details. Plausible. Helpful-sounding. But at this point, the risk estimate is extremely unstable: it could be legitimate investing, or a high-pressure scam.
Our approach works differently:
- Estimate uncertainty across multiple risk dimensions: investment scam, impersonation scam, legitimate high-value transaction
- Identify high-value evidence signals: prior relationship with the recipient, transaction urgency language, and prior account behavioral patterns often provide the highest expected uncertainty reduction
- Route the conversation toward gathering that evidence before proceeding
The risk score remains stable across similar conversations. The question sequence is auditable.
In the plot below, we showcase how this works by comparing risk score trajectories across repeated runs of the same scenarios. In LLM-only scoring, risk estimates fluctuate significantly across turns and runs, making conversation policies and evaluation unstable. With ML-guided scoring, risk converges consistently and monotonically toward the correct outcome. The key difference is not just final accuracy, but stability of the belief trajectory, which is what enables reliable uncertainty estimation, controlled question selection, and ultimately moving from prediction to decision control.
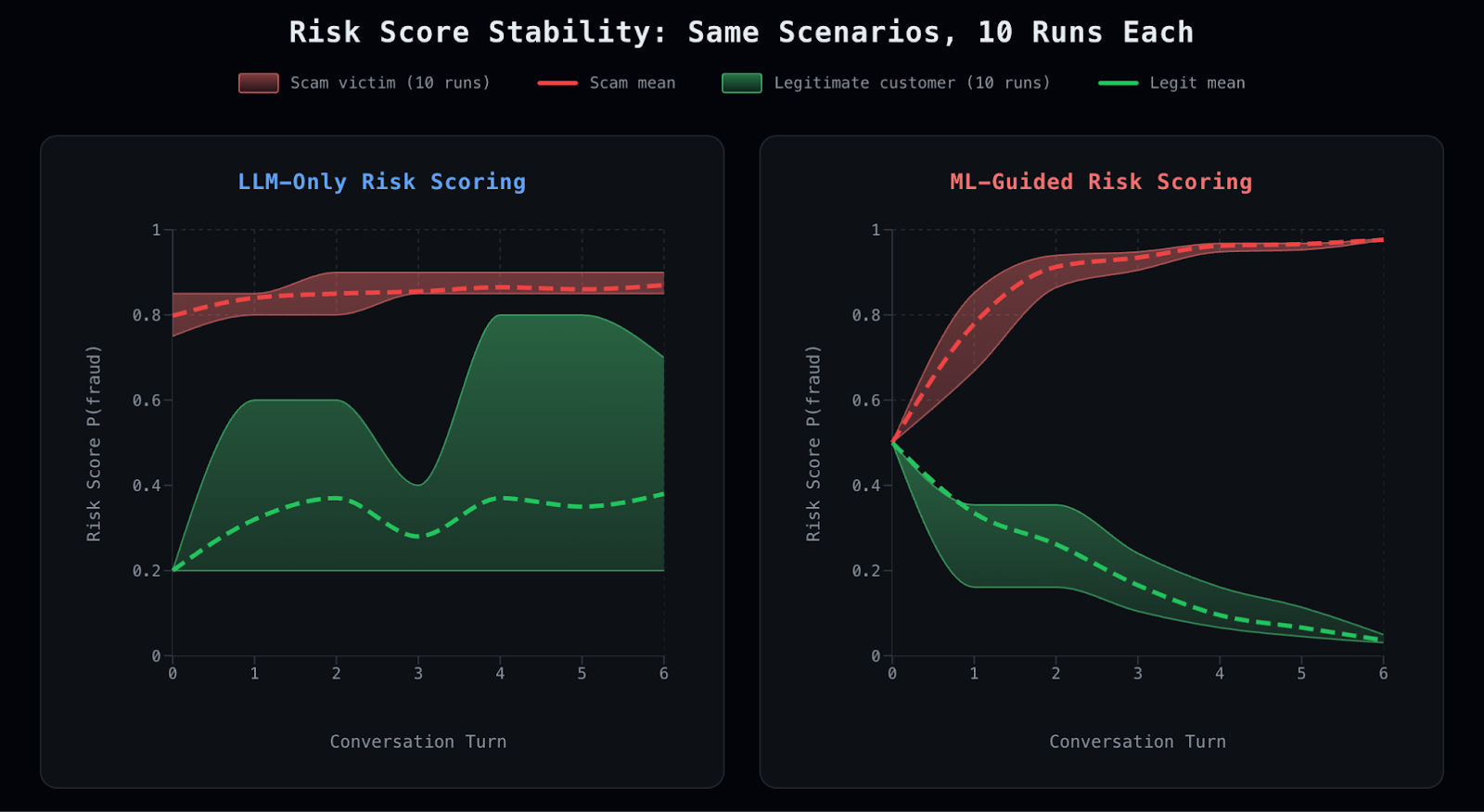
In this experiment, we evaluate two fixed scenarios: a clear scam and a clear legitimate case, repeated 10 times each. The solid lines represent the mean risk score across runs, while the shaded bands show the min–max range. LLM-only scoring produces wide variance across runs, while ML-guided scoring produces tight, stable convergence.
The Takeaway
The shift from prediction to control changes how ML is used inside agentic systems. The goal is no longer only to predict outcomes accurately. It's to actively guide evidence collection, stabilize decision trajectories, and optimize for real-world objectives like customer friction, operational cost, and safety.
In practice, we see the strongest results when combining:
- Structured models to maintain calibrated belief states
- LLMs to interpret language and drive flexible interaction strategies
Much of this is already part of how we build real-world agentic systems, including uncertainty design, evaluation methods for conversational decision systems, and modular frameworks that let domain and product teams safely shape agent behavior without retraining core models.
Threat detection frameworks
Step-by-step instructions for identifying and responding to attacks







Stay informed on threats
Get the latest security insights delivered straight to your inbox each week.